install.packages("gitcreds")
library(gitcreds)
# First time only
gitcreds_set()
# Check
gitcreds_get()Managing data and code
The following introductory section is taken, in slightly adapted form, from Jae Yeon Kim’s “Computational Thinking for Social Scientists.” It is reproduced here for ease of access. To consult the full book, go to https://jaeyk.github.io/comp_thinking_social_science.
The Command Line
What is the command line? The command line or “terminal” is what you’ll recognize from Hollywood portrayals of hackers and script kids—a black screen containing single lines of code, sometimes cascading down the page.
But you all have one on your computers.
On Windows computers, you’ll find this under the name “Command Prompt.” See this guide on how to open.
On Mac, this is called “Terminal”. See this guide. Some also prefer to use an application called “iTerm 2” but they both essentially do the same thing.
The Big Picture
As William Shotts the author of The Linux Command Line put it:
graphical user interfaces make easy tasks easy, while command-line interfaces make difficult tasks possible.
Why bother using the command line?
Suppose that we want to create a plain text file that contains the word “test.” If we want to do this in the command line, you need to know the following commands.
echo: “Write arguments to the standard output” This is equivalent to using a text editor (e.g., nano, vim, emacs) and writing something.> testSave the expression in a file named test.
We can put these commands together like the following:
echo "sth" > test Don’t worry if you are worried about memorizing these and more commands. Memorization is a far less important aspect of learning programming. In general, if you don’t know what a command does, just type <command name> --help. You can do man <command name> to obtain further information. Here, man stands for manual. If you need more user-friendly information, please consider using tldr.
Let’s make this simple case complex by scaling up. Suppose we want to make 100 duplicates of the test file. Below is the one-line code that performs the task!
for i in {1..100}; do cp test "test_$i"; done Let me break down the seemingly complex workflow.
for i in {1..100}.This is a for loop. The numbers 1..100 inside the curly braces{}indicates the range of integers from 1 to 100. In R, this is equivalent to for (i in 1:100) {}
;is used to use multiple commands without making line breaks. ; works in the same way in R.$varreturns the value associated with a variable. Typename=<Your name>. Then, typeecho $name.You should see your name printed. Variable assignment is one of the most basic things you’ll learn in any programming. In R, we do this by using ->
If you have zero experience in programming, I might have provided too many concepts too early, like variable assignment and for loop. However, you don’t need to worry about them at this point. We will cover them in the next chapter.
I will give you one more example to illustrate how powerful the command line is. Suppose we want to find which file contains the character “COVID.” This is equivalent to finding a needle in a haystack. It’s a daunting task for humans, but not for computers. Commands are verbs. So, to express this problem in a language that computers could understand, let’s first find what command we should use. Often, a simple Google or Stack Overflow search leads to an answer.
In this case, grep is the answer (there’s also grep in R). This command finds PATTERNS in each FILE. What follows - are options (called flags): r (recursive), n (line number), w (match only whole words), e (use patterns for matching). rnw are for output control and e is for pattern selection.
So, to perform the task above, you just need one-line code: grep -r -n -w -e "COVID''
Quick reminders - grep: command - -rnw -e: flags - COVID: argument (usually file or file paths)
Let’s remove (=rm) all the duplicate files and the original file. * (any number of characters) is a wildcard (if you want to identify a single number of characters, use ?). It finds every file whose name starts with test_.
rm test_* test Enough with demonstrations. What is this black magic? Can you do the same thing using a graphical interface? Which method is more efficient? I hope that my demonstrations give you enough sense of why learning the command line could be incredibly useful. In my experience, mastering the command line helps automate your research process from end to end. For instance, you don’t need to write files from a website using your web browser. Instead, you can run the wget command in the terminal. Better yet, you don’t even need to run the command for the second time. You can write a Shell script (*.sh) that automates downloading, moving, and sorting multiple files.
UNIX Shell
The other thing you might have noticed is that there are many overlaps between the commands and base R functions (R functions that can be used without installing additional packages). This connection is not coincident. UNIX preceded and influenced many programming languages, including R.
The following materials on UNIX and Shell are adapted from [the software carpentry](https://bids.GitHub.io/2015-06-04-berkeley/shell/00-intro.html.
Unix
UNIX is an operating system + a set of tools (utilities). It was developed by AT & T employees at Bell Labs (1969-1971). From Mac OS X to Linux, many of the current operation systems are some versions of UNIX. Command-line INTERFACE is a way to communicate with your OS by typing, not pointing, and clicking.
For this reason, if you’re using Mac OS, then you don’t need to do anything else to experience UNIX. You’re already all set.
If you’re using Windows, you need to install either GitBash (a good option if you only use Bash for Git and GitHub) or Windows Subsystem (highly recommended if your use case goes beyond Git and GitHub). For more information, see this installation guideline. If you’re a Windows user and don’t use Windows 10, I recommend installing VirtualBox.
UNIX is old, but it is still mainstream, and it will be. Moreover, the UNIX philosophy (“Do One Thing And Do It Well”)—minimalist, modular software development—is highly and widely influential.
AT&T Archives: The UNIX Operating System
Unix50 - Unix Today and Tomorrow: The Languages
Kernel
The kernel of UNIX is the hub of the operating system: it allocates time and memory to programs. It handles the filestore (e.g., files and directories) and communications in response to system calls.
Shell
The shell is an interactive program that provides an interface between the user and the kernel. The shell interprets commands entered by the user or supplied by a Shell script and passes them to the kernel for execution.
Human-Computer interfaces
At a high level, computers do four things:
- run programs
- store data
- communicate with each other
- interact with us (through either CLI or GUI)
The Command Line
This kind of interface is called a command-line interface, or CLI, to distinguish it from the graphical user interface, or GUI, that most people now use.
The heart of a CLI is a read-evaluate-print loop, or REPL: when the user types a command and then presses the enter (or return) key, the computer reads it, executes it, and prints its output. The user then types another command, and so on until the user logs off.
If you’re using RStudio, you can use terminal inside RStudio (next to the “Console”). (For instance, type Alt + Shift + M)
The Shell
This description makes it sound as though the user sends commands directly to the computer and sends the output directly to the user. In fact, there is usually a program in between called a command shell.
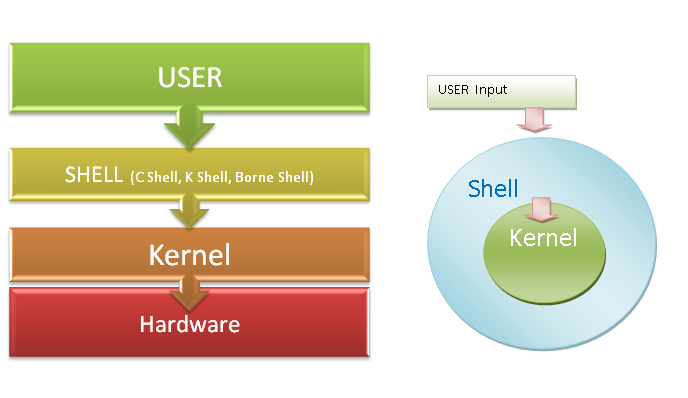
What the user types go into the shell; it figures out what commands to run and orders the computer to execute them.
Note, the shell is called the shell: it encloses the operating system to hide some of its complexity and make it simpler to interact with.
A shell is a program like any other. What’s special about it is that its job is to run other programs rather than do calculations itself. The commands are themselves programs: when they terminate, the shell gives the user another prompt ($ on our systems).
Bash
The most popular Unix shell is Bash, the Bourne Again Shell (so-called because it’s derived from a shell written by Stephen Bourne — this is what passes for wit among programmers). Bash is the default shell on most modern implementations of Unix and in most packages that provide Unix-like tools for Windows.
Why Shell?
Using Bash or any other shell sometimes feels more like programming than like using a mouse. Commands are terse (often only a couple of characters long), their names are frequently cryptic, and their output is lines of text rather than something visual like a graph.
On the other hand, the shell allows us to combine existing tools in powerful ways with only a few keystrokes and set up pipelines to handle large volumes of data automatically.
In addition, the command line is often the easiest way to interact with remote machines (explains why we learn Bash before learning Git and GitHub). If you work in a team and your team manages data in a remote server, you will likely need to get access the server via something like ssh.
Our first command
The part of the operating system responsible for managing files and directories is called the file system. It organizes our data into files, which hold information, and directories (also called “folders”), which hold files or other directories.
Several commands are frequently used to create, inspect, rename, and delete files and directories. To start exploring them, let’s open a shell window:
jae@jae-X705UDR:~$ Let’s demystify the output above. There’s nothing complicated.
- jae: a specific user name
- jae-X705UDR: your computer/server name
~: current directory (~= home)$: a prompt, which shows us that the shell is waiting for input; your shell may show something more elaborate.
Type the command whoami, then press the Enter key (sometimes marked Return) to send the command to the shell.
The command’s output is the ID of the current user, i.e., it shows us who the shell thinks we are:
$ whoami
# Should be your user name
jae More specifically, when we type whoami the shell, the following sequence of events occurs behind the screen.
- Finds a program called
whoami, - Runs that program,
- Displays that program’s output, then
- Displays a new prompt to tell us that it’s ready for more commands.
Communicating to other systems
In the next unit, we’ll focus on the structure of our own operating systems. But our operating systems rarely work in isolation; we often rely on the Internet to communicate with others! You can visualize this sort of communication within your own shell by asking your computer to ping (based on the old term for submarine sonar) an IP address provided by Google (8.8.8.8); in effect, this will test whether your Internet is working.
$ ping 8.8.8.8Note: Windows users may have to try a slightly different alternative:
$ ping -t 8.8.8.8(Thanks Paul Thissen for the suggestion!). Note: press ctrl + C to stop your terminal pinging!
File system organization
Next, let’s find out where we are by running a pwd command (print working directory).
At any moment, our current working directory is our current default directory, i.e., the directory that the computer assumes we want to run commands in unless we explicitly specify something else.
Here, the computer’s response is /home/jae, which is the home directory:
$ pwd
/home/jaeHome Directory
The home directory path will look different on different operating systems. For example, on Linux, it will look like
/home/jae,and on Windows, it will be similar toC:\Documents and Settings\jae.Note that it may look slightly different for different versions of Windows.
whoami
If the command to find out who we are is
whoami,the command to find out where we are ought to be calledwhereami,so why is itpwdinstead? The usual answer is that in the early 1970s, when Unix was first being developed, every keystroke counted: the devices of the day were slow, and backspacing on a teletype was so painful that cutting the number of keystrokes to cut the number of typing mistakes was a win for usability. The reality is that commands were added to Unix one by one, without any master plan, by people who were immersed in its jargon.The good news: because these basic commands were so integral to the development of early Unix, they have stuck around and appear (in some form) in almost all programming languages.
If you’re working on a Mac, the file structure will look similar, but not identical.
We know that our current working directory /home/jae is stored inside /home because /home is the first part of its name. Similarly, we know that /home is stored inside the root directory / because its name begins with /.
Listing
Let’s see what’s in your home directory by running ls (**list files and directories):
$ ls
Applications Dropbox Pictures
Creative Cloud Files Google Drive Public
Desktop Library Untitled.ipynb
Documents Movies anaconda
Downloads Music file.txtls prints the names of the files and directories in the current directory in alphabetical order, arranged neatly into columns.
We can make ls more useful by adding flags. For instance, you can make your computer show only directories in the file system using the following command. Here -F flag classifies files based on some types. For example, / indicates directories.
ls -F /The leading / tells the computer to follow the path from the file system’s root, so it always refers to exactly one directory, no matter where we are when we run the command.
If you want to see only directories in the current working directory, you can do the following. (Remember ^? This wildcard identifies a single number of characters. In this case, `d’.)
ls -l | grep "^d"What if we want to change our current working directory? Before we do this, pwd shows us that we’re in /home/jae, and ls without any arguments shows us that directory’s contents:
$ pwd
/home/jae
$ ls
Applications Dropbox Pictures
Creative Cloud Files Google Drive Public
Desktop Library Untitled.ipynb
Documents Movies anaconda
Downloads Music file.txtUse relative paths (e.g., ../spring_2021/references.md) whenever it’s possible so that your code is not dependable on how your system is configured.
Additional tips
How can I find pdf files in Downloads using the terminal? Remember * wildcard?
cd Downloads/
find *.pdfAlso, note that you don’t need to type every character. Type the first few characters, then press TAB (autocomplete). This is called tab-completion, and we will see it in R as we go on.
Moving around
We can use cd (change directory) followed by a directory name to change our working directory. First we need to get the file path, which we can do on a Mac the following ways and on a Windows computer like this.
$ cd Desktopcd doesn’t print anything, but if we run pwd after it, we can see that we are now in /home/jae/Desktop.
If we run ls without arguments now, it lists the contents of /home/jae/Desktop, because that’s where we now are:
$ pwd
/home/jae/DesktopWe now know how to go down the directory tree: how do we go up? We could use an absolute path:
$ cd /home/jae/but it’s almost always simpler to use cd .. to go up one level:
$ pwd
/home/jae/Desktop
$ cd .... is a special directory name meaning “the directory containing this one,” or more succinctly, the parent of the current directory. Sure enough, if we run pwd after running cd .., we’re back in /home/jae/:
$ pwd
/home/jae/The special directory .. doesn’t usually show up when we run ls. If we want to display it, we can give ls the `-a’ flag:
$ ls -a
. .localized Shared
.. Guest rachel-a' stands for "show all"; it forceslsto show us file and directory names that begin with., such as..`.
Hidden Files: For Your Own Protection
As you can see, many other items just appeared when we enter
ls -a'. These files and directories begin with.` followed by a name. Usually, files and directories hold important programmatic information. They are kept hidden so that users don’t accidentally delete or edit them without knowing what they’re doing.
As you can see, it also displays another special directory that’s just called ., which means “the current working directory”. It may seem redundant to have a name for it, but we’ll see some uses for it soon.
Additional tips
The above navigating exercises help us know about cd command, but not very exciting. So let’s do something more concrete and potentially useful. Let’s say you downloaded a file using your web browser and locate that file. How could you do that?
Your first step should be learning more about the ls command. You can do that by Googling or typing ls --help. By looking at the documentation, you can recognize that you need to add -t (sort by time). In other words, here we’re looking for the most recently created files in our working directory.
Then, what’s |? It’s called pipe, and it chains commands. For instance, if <command 1> | <command 2>, then command1’s output will be command2’s input. head list the first ten lines of a file. -n1 flag makes it show only the first line of the output (n1).
# Don't forget to use TAB completion
cd Downloads/
ls -t | head -n1Yeah! We can do more cool things. For example, how can you find the most recently downloaded PDF file? You can do this by combining the two neat tricks you learned earlier.
ls -t | find *.pdf | head -n1 Creating, copying, removing, and renaming files
Creating files
- First, let’s create an empty directory named exercise
mkdir exercise You can check whether the directory is created by typing
ls. If the print format is challenging to read, add-lflag. Did you notice the difference?Let’s move to the
exercisesubdirectory and create a file named test
cd exercise ; touch test ; ls - Read test
cat test - Hmn. It’s empty. Let’s add something there.
>= overwrite
echo "something" > test ; cat test - Yeah! Can you add more?
>>= append
echo "anything" >> test ; cat test - Removing “anything” from
testis a little bit more complex because you need to know how to usegrep(remember that we used this command in the very first example). Here, I just demonstrate that you can do this task using Bash, and let’s dig into this more when we talk about working with text files.
grep -v "anything" testCopying and Removing Files
- Can we make a copy of
test? Yes!
cp test test_1; cat - Can we make 100 copies of
test?Yes!
You can do this
cp test test_1
cp test test_2
cp test test_3
... or
for i in {1..100}; do cp test "test_$i"; done - Can you remove all of the
test_files?
You can do this
rm test_1
rm test_2
rm test_3
...or
rm test_*Which one do you like?
- Let’s remove the directory.
cd ..
rm exercise/The rm command should not work because exercise is not a file. Type rm --help and see which flag will be helpful. It might be `-d’ (remove empty directories).
rm -d exercise/ Oops. Still not working because the directory is not empty. Try this. Now, it works.
rm -r exercise/ What’s -r? It stands for recursion (e.g., Recursion is a very powerful idea in programming and helps solve complex problems. We’ll come back to it many times (e.g., purrr::reduce() in R).
What on Earth is Recursion? - Computerphile
Renaming files
- Using
mv
First, we will learn how to move files and see how it’s relevant for renaming files.
# Create two directories
mkdir exercise_1 ; mkdir exercise_2
# Check whether they were indeed created
find exer*
# Create an empty file
touch exercise_1/test
# Move to exercise_1 and check
cd exercise_1 ; ls
# Move this file to exercise_2
mv test ../exercise_2
# Move to exercise_2 and check
cd exercise_2 ; ls What has mv got to do with renaming?
- [mv] [source] [destination]
mv test new_test ; ls - Using
rename
mv is an excellent tool to rename one file. But how about renaming many files? (Note that your pwd is still exercise_2 where you have the new_test file.)
for i in {1..100}; do cp new_test "test_$i.csv"; done Then install rename. Either sudo apt-get install -y rename or brew install rename (MacOS).
Basic syntax: rename [flags] perlexpr (Perl Expression) files. Note that Perl is another programming language.
# Rename every csv file to txt file
rename 's/.csv/.txt/' *.csv
# Check
ls -lThe key part is s/.csv/.txt/ = s/FIND/REPLACE
Can you perform the same task using GUI? Yes, you can, but it would be more time-consuming. Using the command line, you did this via just one-liner(!). Keith Brandnam wrote an excellent book titled UNIX and Perl to the Rescue! (Cambridge University Press 2012) that discusses how to use UNIX and Perl to deal with massively large datasets.
Working with CSV and text files
- Download a CSV file (Forbes World’s Billionaires lists from 1996-2014). For more on the data source, see this site.
wget https://corgis-edu.github.io/corgis/datasets/csv/billionaires/billionaires.csvNote you may first need to brew install wget (MacOS). To check whether it is installed on your machine, type:
wget -VIf you’re using Windows and you don’t find wget, try following these steps.
- Read the first two lines.
catis printing, andheadshows the first few rows.-n2limits these number of rows equals 2.
Additional tips 1 If you have a large text file, cat prints everything at once is inconvenient. The alternative is using less.
cat billionaires.csv | head -n2To print the whole data in more legible format with column separation, we can type:
cat billionaires.csv | column -t -s, | less -S- Check the size of the dataset (2615 rows). So, there are 2014 observations (n-1 because of the header).
wcprints newline, word, and byte counts for each file. If you runwcwithout-lflag, you get the following:2615 (line) 20433 (word) 607861 (byte) billionaires.csv
wc -l billionaires.csv- How about the number of columns?
sedis a stream editor and very powerful when it’s used to filter text in a pipeline. For more information, see this article. You’ve already seens/FIND/REPLACE.Here, the pattern we are using iss/delimiter/\n/g.We’ve seen that the delimiter is,so that’s what I plugged in the command below.
head -1 billionaires.csv | sed 's/,/\n/g' | nlAdditional tips 2 The other cool command for text parsing is awk. This command is handy for filtering.
- This is the same as using
cat.So, what’s new?
awk '{print}' billionaires.csv - This is new.
awk '/China/ {print}' billionaires.csv- Let’s see only the five rows. We filtered rows so that every row in the final dataset contains ‘China.’
awk '/China/ {print}' billionaires.csv | head -n5 - You can also get the numbers of these rows.
awk '/China/ {print NR}' billionaires.csv User roles and file permissions
If you need admin access, use
sudo.For instance,sudo apt-get install <package name>installs the package.To run a Shell script (.sh), you need to change its file mode. You can make the script executable by typing
chmod +x <Shell script>.Then, you can run it by typing
./pdf_copy_sh.The.here refers to the current working directory.
Note: Other options to do the same thing: sh pdf_copy_sh. or bash pdf_copy_sh.
Writing your first Shell script (.sh)
Finally, we’re learning how to write a Shell script (a file that ends with .sh). Here I show how to write a Shell script that creates a subdirectory called /pdfs under /Download directory, then find PDF files in /Download and copy those files to pdfs. Essentially, this Shell script creates a backup. Name this Shell script as ‘pdf_copy.sh.’
#!/bin/sh # Stating this is a Shell script.
mkdir /home/jae/Downloads/pdfs # Obviously, in your case, this file path would be incorrect.
cd Downloads
cp *.pdf pdfs/
echo "Copied pdfs"You should now have a backup of all the PDFs that were in you Downloads folder!
Additional resources
Using make and writing Makefile (in C++ or C) by Programming Knowledge
References
The Unix Workbench by Sean Kross
The Unix Shell, Software Carpentry
Data Science at the Command Line by Jeroen Janssens
Obtaining, Scrubbing, and Exploring Data at the Command Line by Jeroen Janssens from YPlan, Data Council
Shell Tools and Scripting, ./missing-semester, MIT
Command-line Environment, ./missing-semester, MIT
Git and GitHub
The Big Picture
The most important point
Backup != Version control
If you do version control, you need to save your raw data in your hard disk, external drive, or cloud, but nothing else. In other words, anything you are going to change should be subject to version control (also, it’s not the same as saving your code with names like 20200120_Kim or something like that). Below, I will explain what version control is and how to do it using Git and GitHub.

Version control system
According to GitHub Guides, a version control system “tracks the history of changes as people and teams collaborate on projects together.” Specifically, it helps to track the following information:
- Which changes were made?
- Who made the changes?
- When were the changes made?
- Why were changes needed?
Git is a case of a distributed version control system, common in open source and commercial software development. This is no surprise given that Git was originally created to deal with Linux kernel development.
The following images, from Pro Git, show how a centralized (e.g., CVS, Subversion, and Perforce) and decentralized VCS (e.g., Git, Mercurial, Bazzar or Darcs) works differently.
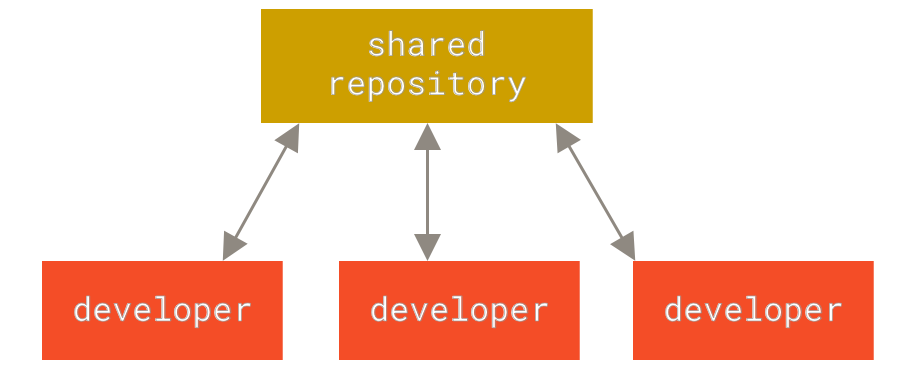
Figure 2. Centralized VCS.
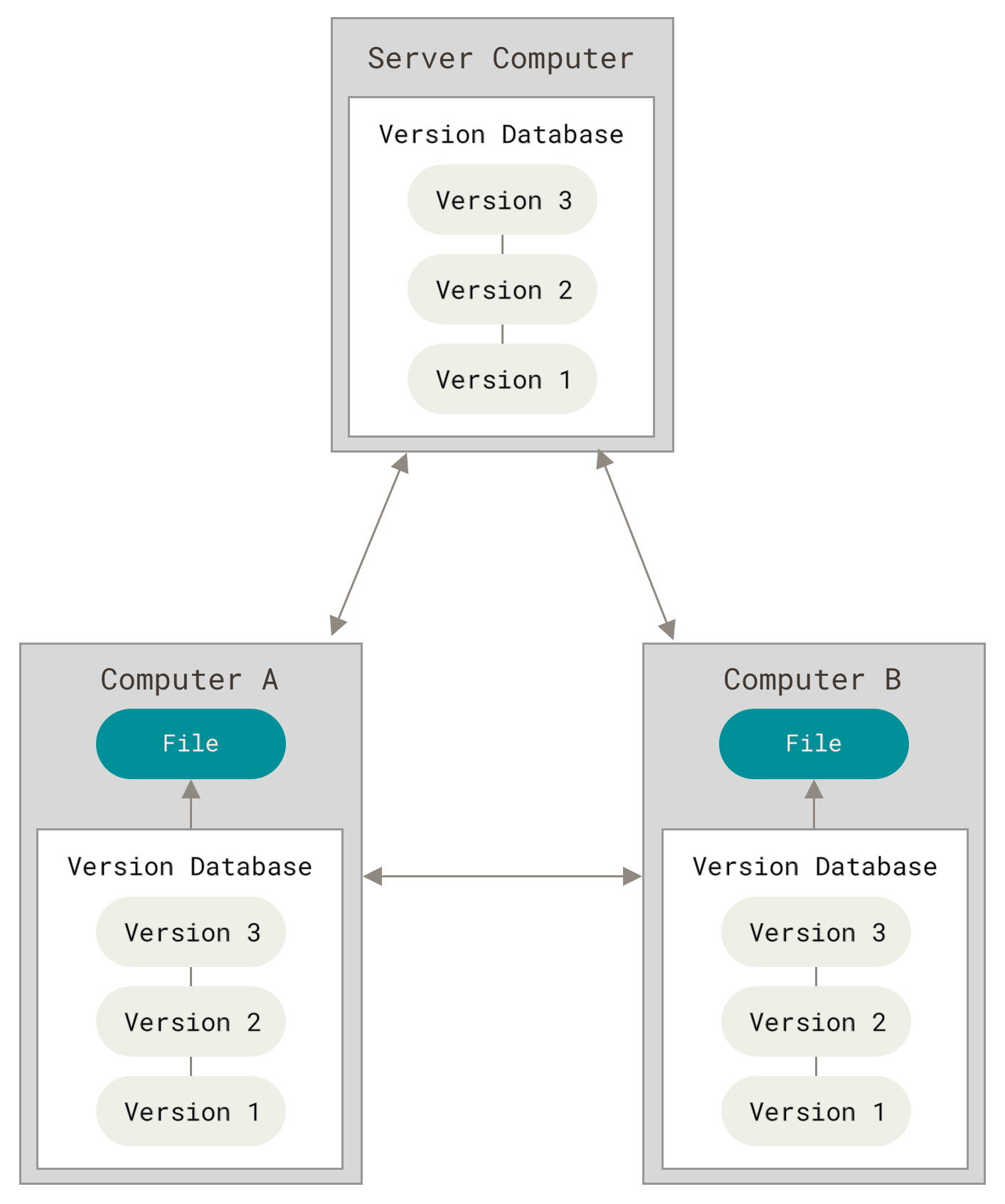
Figure 3. Decentralized VCS.
For more information on the varieties of version control systems, please read Petr Baudis’s review on that subject.
Webcast • Introduction to Git and GitHub • Featuring Mehan Jayasuriya, GitHub Training & Guides
For more information, see GitHub’s introductory tutorials.
Setup
Signup
- Make sure you have installed Git ([tutorial]).
git --version
# git version 2.xx.x- If you haven’t, please sign up for a GitHub account: https://github.com/
- If you’re a student, please also sign up for GitHub Student Developer Pack: https://education.github.com/pack Basically, you can get a GitHub pro account for free (so why not?).
- Access GitHub using Hypertext Transfer Protocol Secure (HTTPS) or Secure Shell (SSH).
HTTPS
Create a personal access token. Follow this guideline: https://docs.github.com/en/github/authenticating-to-github/creating-a-personal-access-token
Store your credential somewhere safe. You can use an R package like this gitcreds and credentials to do so.
- If you get asked to provide your password when you pull or push, the password should be your GitHub token (to be precise, personal access token).
SSH
If possible, I highly recommend using SSH. Using SSH is safer and also makes connecting GitHub easier. SSH has two keys (public and private). The public key could be stored on any server (e.g., GitHub) and the private key could be saved in your client (e.g., your laptop). Only when the two are matched, the system unlocks.
First, read this tutorial and create SSH keys.
Second, read this tutorial and check the keys and provide the public key to GitHub and add the private key to ssh-agent.
Next time, if you want to use SSH, remember the following.
# SSH
git@github.com:<user>/<repo>.git
# HTTPS
https://github.com/<user>/<repo>.gitConfigurations
- Method 1: using the terminal
# User name and email
$ git config --global user.name "Firstname Lastname"
$ git config --global user.email username@school.extensionThe first of this config calls asks for your user name as specified on Github.
- Method 2: using RStudio
install.packages("usethis")
library(usethis)
use_git_config(user.name = "<Firstname Lastname>",
user.email = "<username@school.extension>")You’re all set!
Cloning a repository
Let’s clone a repository. Here, we’re actually going to clone the repository for my course book.
git clone https://github.com/cjbarrie/CS-EDIf you cd CS-ED/ you can move to the cloned course repository. Cloning: copying a public GitHub repo (remote) -> Your machine
If you accidentally changed something up in your local copy, you can just overwrite the local copy using the remote repo and make it exactly looks like the latter.
# Download content from a remote repo
git fetch origin
# Going back to origin/main
git reset --hard origin/main
# Remove local files
git clean -fAdditional tips You can see cloning and forking on GitHub, and they sound similar. Let me differentiate them.
Cloning: creating a local copy of a public GitHub repo. In this case, you have writing access to the repo.
Forking (for open source projects): creating a copy of a public GitHub repo to your GitHub account, then you can clone it. In this case, you don’t have writing access to the repo. You need to create pull requests if you want your changes reflected in the original repo. Don’t worry about pull requests, as I will explain the concept shortly. For more information, see this documentation.
Making a repository
Create a new directory and move there. Then initialize
# new directory
$ mkdir code_exercise
# move
$ cd code_exercise
# initialize
$ git init Alternatively, you can create a Git repository via GitHub and then clone it on your local machine. Perhaps, it is an easier path for new users (I also do this all the time).
We can do this in the following way. First, go to you Github profile and click on the Repositories tab. Then click on “New.” You’ll be asked to give the Repo a name and an optional description. I highly recommend adding README (more on why we do this in the following subsection). We will discuss later on what a .gitignore file is for.
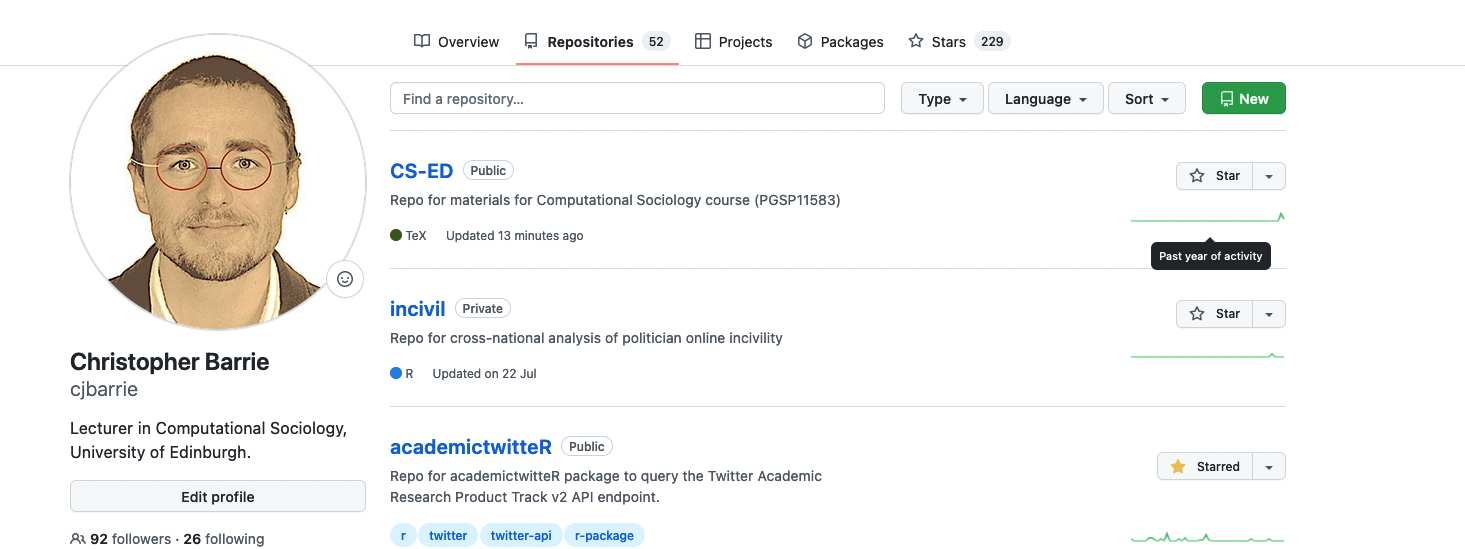
Once you have created your Repo you can then get the files on your local machine by calling the following:
$ git clone /path/to/repositoryWhere the path will just be the URL for your Repository.
Additional tips If you’re unfamiliar with basic Git commands, please refer to this Git cheat sheet.
Commit changes
These features show how Git works as a version control system.
If you edited files or added new ones, you need to update your repository. In Git terms, this action is called committing changes.
My current pwd is CS-ED. I created a text file named test containing text chris. You can check the file exists by typing `find “test```.
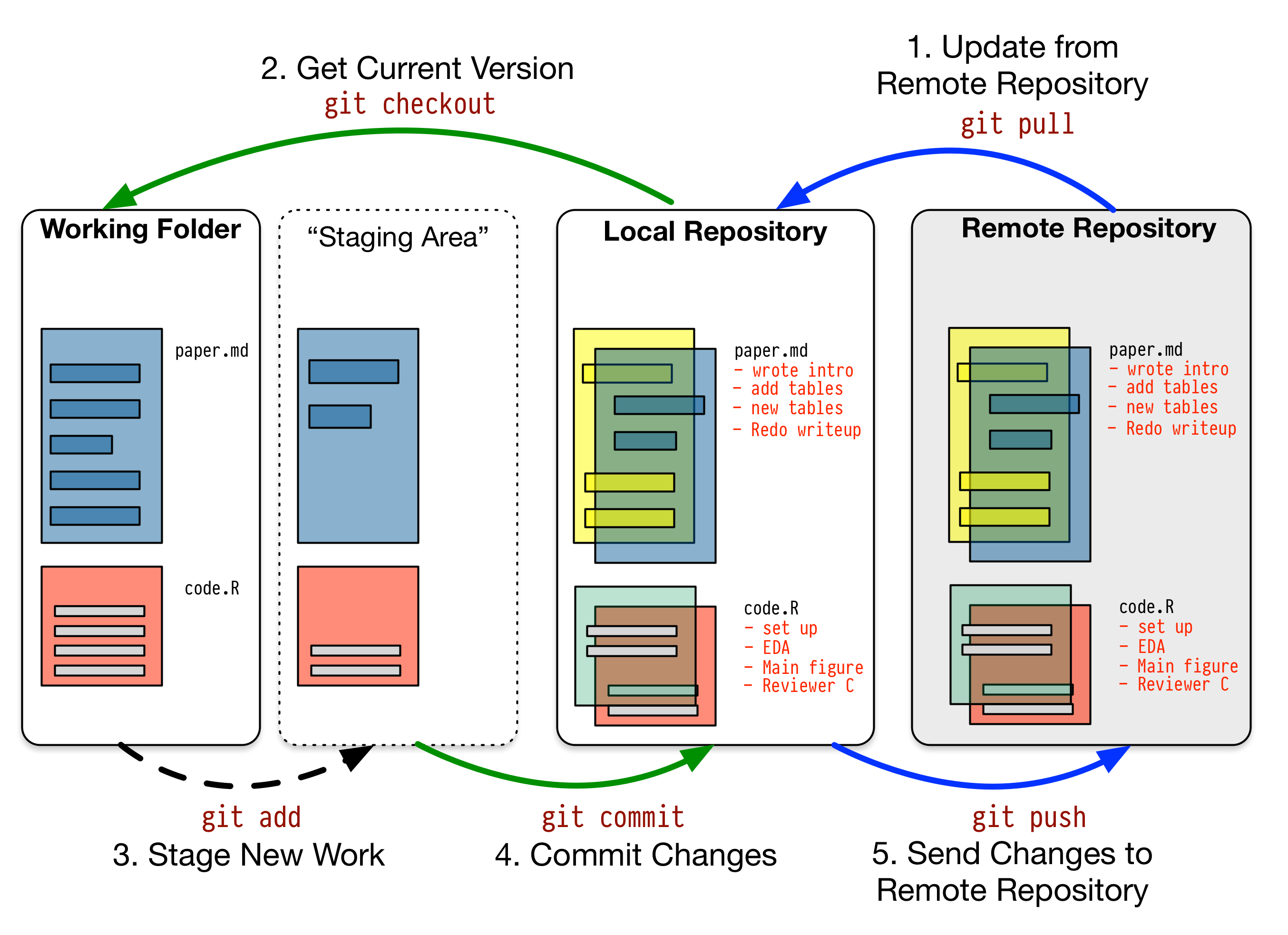
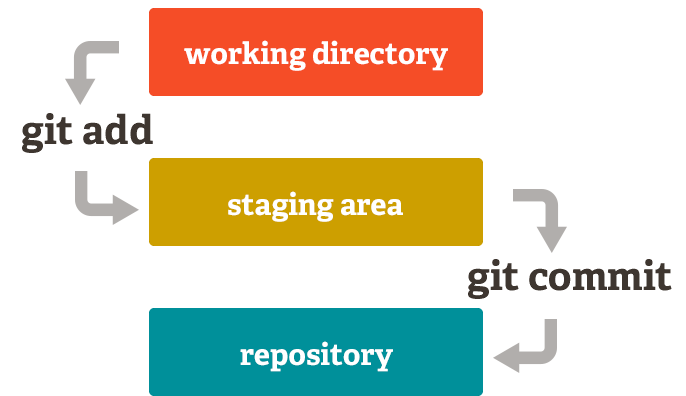
The following is a typical workflow to reflect this change to the remote.
$ git status # check what's changed.
$ git add . # update every change. In Git terms, you're staging.
$ git add file_name # or stage a specific file.
$ git commit -m "your comment" # your comment for the commit.
$ git push origin main # commit the change. Origin is a default name given to a server by Git. `origin main` are optional. Another image from Pro Git nicely illustrates this process.
If you made a mistake, don’t panic. You can’t revert the process.
git reset --soft HEAD~1 # if you still want to keep the change, but you go back to t-1
git reset --hard HEAD~1 # if you're sure the change is unnecessary Writing an informative commit is essential. To learn how to do this better, see the following video:
Your Commits Should Tell a Story • Featuring Eliza Brock Marcum, GitHub Training & Guides
Push and pull (or fetch)
These features show how Git works as a collaboration tool.
If you have not already done it, let’s clone the PS239T directory on your local machine.
$ git clone https://github.com/PS239T/spring_2021 # clone Additional tips 1
If you try to remove spring_2021 using rm -r spring_2021/, you will get an error about the write-protected regular file. Then, try rm -rf spring_2021/.
Then, let’s learn more about the repository.
$ git remote -v You should see something like the following:
origin git@github.com:PS239T/spring_2021 (fetch)
origin git@github.com:PS239T/spring_2021 (push)If you want to see more information, then type git remote show origin.
Previously, we learned how to send your data to save in the local machine to the remote (the GitHub server). You can do that by editing or creating files, committing, and typing git push.
Instead, if you want to update your local data with the remote data, you can type git pull origin (something like pwd in bash). Alternatively, you can use fetch (retrieve data from a remote). Git retrieves the data and merges it into your local data when you do that.
$ git fetch originAdditional tips 2
Developers usually use PR to refer pull requests. When you are making PRs, it’s recommended to scope down (small PRs) because they are easier on reviewers and to test. To learn about how to accomplish this, see this blog post by Sarah Drasner.
Branching
It’s an advanced feature of Git’s version control system that allows developers to “diverge from the main line of development and continue to do work without messing with that main line,” according to Scott Chacon and Ben Straub.
If you start working on a new feature, create a new branch.
$ git branch new_features
$ git checkout new_featuresYou can see the newly created branch by typing git branch.
In short, branching makes Git works like a mini file system.
Other useful commands
- For tracking history
$ git diff # to see what changed (e.g., inside a file)
$ git log # to track who committed what
$ git log -S <pattern> # you can find a log that contains the pattern
$ git checkout # to recover old files
$ git revert # revert to the previous commit - For removing and renaming files
$ git rm file_name # remove
$ git mv old_file_name new_file_name # rename a file How about removing a directory only from GitHub but not local?
git rm -r --cached <directory>
git commit -m "<message>"
git pushCollaborations
Two options.
Deployment: GitHub Pages
Useful to deploy websites. I used the GitHub page to deploy this book.
Webcast • Get Started with GitHub Pages • Featuring Dani Traphagen, GitHub Training & Guides
Tracking progress: GitHub Issues
Useful to collect and respond to questions and suggestions (e.g., bug reports and feature suggestions) on the projects on which you’re working.
Webcast • GitHub Issues • Using Projects for feature planning
Project management: GitHub Dashboards
I use GitHub dashboards for almost every project that I have done.
GitHub Projects Demo: Automation, Kanban, Scrum, Issues, Pull Request, Milestones, Issues, Tasks by Brandan Jones
The Big Picture
When you are reading this section, please note that you’ve already grasped some key concepts behind R programming language (functions and objects).
UNIX Commands (cat) = R Functions (print) Files = R Objects
Motivation
Why do you need to make your research computationally reproducible?: for your own sanity and for public benefit. That is, it makes your life a whole lot easier to have a history of what you’ve done and why. And it makes research more transparent and reproducible: others can see what you’ve done, how you’ve done it—and they can go off and build on this.
How to organize files in a project
You won’t be able to reproduce your project unless it is efficiently organized.
Step 1. Environment is part of your project. If someone can’t reproduce your environment, they won’t be able to run your code.
- Launch R Studio. Tools > Global Options. You should not check Restore .RData into workspace at startup. Also, set the saving workspace option to NEVER.
Step 2. For each project, create a project directory named after the project.
name_of_the_project
- 01_script_that_does_first_thing.R
- 02_script_that_does_second_thing.R
- data:
- raw
- processed (all processed, cleaned, and tided)
- figures
- functions
- reports (PDF, HTML, TEX, etc.,)
- results (model outcomes, etc.,)
- .gitignore (for Git)
- name_of_project.Rproj (for R)
- README.md (for Git)
# Don't name it a project. Instead, use a more informative name. For instance, `us_election`, not `my_project.`
dir.create("../us_election")Step 3. Launch R Studio. Choose File > New project > Browse existing directories > Create project. This means each project has its own workspace.
Step 4. Organize files by putting them in separate subdirectories and sensibly naming them.
Treat raw data as read-only (raw data should be RAW!) and put it in the
datasubdirectory.- Again, note that version control does not need to replace backup. You still need to back up your raw data.
dir.create(here::here("us_election", "data"))And separate into raw and processed
dir.create(here::here("us_election/data/", "raw"))
dir.create(here::here("us_election/data/", "processed"))- Separate figures into the
figuressubdirectory.
dir.create(here::here("us_election", "figures"))- Put any reports in the
reportssubdirectory.
dir.create(here::here("us_election", "reports"))- Put generated results in the `results`` subdirectory and treat them as disposable.
dir.create(here::here("us_election", "results"))- Put your custom functions in the
functionssubdirectory.
dir.create(here::here("us_election", "functions"))Are you tired of creating these directories one by one? Why not automate? See the following example. You can save this function as a rscript (e.g., setup.r) and run it in the terminal using Rscript <script name>.
if (!require(pacman)) install.packages("pacman")
# Load here
pacman::p_load(
purrr, # functional programming
here # computational reproducibility
)
# Custom function
create_dirs <- function(name) {
dir.create(here(name))
}
# Apply function
purrr::map(c("data", "figures", "reports", "results", "functions"), create_dirs)Of course, you don’t have to use these exact names. But here’s an example of how I tend to structure my directories—and you’ll see it follows this basic structure.
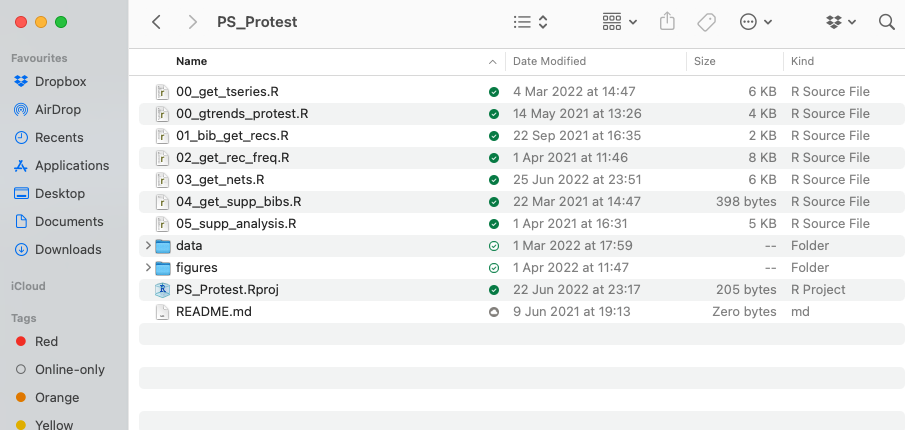
How to organize code in an R markdown file
In addition to environment, workflow is an essential component of project efficiency and reproducibility.
What is R markdown? An R package, developed by Yihui Xie, provides an authoring framework for data science. Xie is also a developer of many widely popular R packages such as
knitr,xaringan(cool kids use xaringan not Beamer these days),blogdown(used to create my personal website), andbookdown(used to create this book) among many others.- Many applications: reports, presentations, dashboards, websites
- Check out Communicating with R markdown workshop by Alison Hill (RStudio)
- Alison Hill is a co-author of
blogdown: Creating Websites with R Markdown.
- Alison Hill is a co-author of
- Key strengths: dynamic reporting + reproducible science + easy deployment
- Many applications: reports, presentations, dashboards, websites

R Markdown The bigger picture - Garrett Grolemund
R-Ladies Oslo (English) - Reports to impress your boss! Rmarkdown magic - Athanasia Mowinckel
- R Markdown basic syntax
# Header 1
## Header 2
### Header 3- Use these section headers to indicate workflow.
# Import packages and data
# Tidy data
# Wrangle data
# Model data
# Visualize dataPress ctrl + shift + o. You can see a document outline based on these headers. This is a nice feature for finding the code you need to focus on.
If your project’s scale is large, divide these sections into files and numbers and save them in the code subdirectory.
- 01_wrangling.Rmd
- 02_modeling.Rmd …
Making a project computationally reproducible
setwd(): set a working directory.Note that using
setwd()is not a reproducible way to set up your project. For instance, none will be able to run the following code except me.
# Set a working directory
setwd("/home/jae/starwars")
# Do something
ggplot(mtcars, aes(x = mpg, y = wt)) +
geom_point()
# Export the object.
# dot means the working directory set by setwd()
ggsave("./outputs/example.png") # This is called relative path Instead, learn how to use
here()’.Key idea: separate workflow (e.g., workspace information) from products (code and data). For more information, please read Jenny Bryan’s excellent piece on project-oriented workflow.
Example
# New: Reproducible
ggplot(mtcars, aes(x = mpg, y = wt)) +
geom_point()
ggsave(here("project", "outputs", "example.png"))- How
hereworks
here() function shows what’s the top-level project directory.
here::here()- Build a path including subdirectories
here::here("project", "outputs")
#depth 1 #depth 2How
heredefines the top-level project directory. For example, the following list came from the here package vignette).Is a file named .here present?
Is this an RStudio Project? (Note that we already set up an RStudio Project! So, if you use RStudio’s project feature, then you are ready to use
here.)Is this an R package? Does it have a DESCRIPTION file?
Is this a remake project? Does it have a file named
remake.yml?Is this a projectile project? Does it have a file named
.projectile?Is this a checkout from a version control system? Does it have a directory named
.gitor.svn? Currently, only Git and Subversion are supported.If there’s no match then use
set_here()to create an empty.herefile.
References
Code and data management
- “Code and Data for the Social Sciences: A Practitioner’s Guide” by Matthew Gentkow and Jesse M. Shapiro
Project-oriented research
Computational reproducibility
Project Management with RStudio by Software Carpentry
Initial steps toward reproducible research by Karl Broman
Version control
Version Control with Git by Software Carpentry
The Plain Person’s Guide to Plain Text Social Science by Kieran Healy