library(tidyverse)
library(readxl)
library(tuber)
yt_oauth("431484860847-1THISISNOTMYREALKEY7jlembpo3off4hhor.apps.googleusercontent.com","2niTHISISMADEUPTOO-l9NPUS90fp")
#get related videos
startvid <- "1Gp7xNnW5n8"
rel_vids <- get_related_videos(startvid, max_results = 50, safe_search = "none")Worksheet 3: Bots and Experiments
For this worksheet, we will go through how to set up an experiment with the YouTube Recommendation algorithm.
This will partially replicate the technique used in the article by Haroon et al. (2022).
Using the YouTube API
In order to use the YouTube API, we’ll first need to get our authorization token. These can be obtained by anybody, with or without an academic profile (i.e., unlike academictwitteR) in previous worksheets.
In order to get you authorization credentials, you can follow this guide. You will need to have an account on the Google Cloud console in order to do this. The main three steps are to:
- create a “Project” on the Google Cloud console;
- to associate the YouTube API with this Project;
- to enable the API keys for the API
Once you have created a Project (here: called “tuberalt1” in my case) you will see a landing screen like this.
We can then get our credentials by navigating to the menu on the left hand side and selecting credentials:
We have two pieces of information stored here that we will need. These are our “client ID” and “API key”. The client ID is referred to below as our “app ID” in the tuber packaage and the API key shown below is our “app secret” in the tuber package.
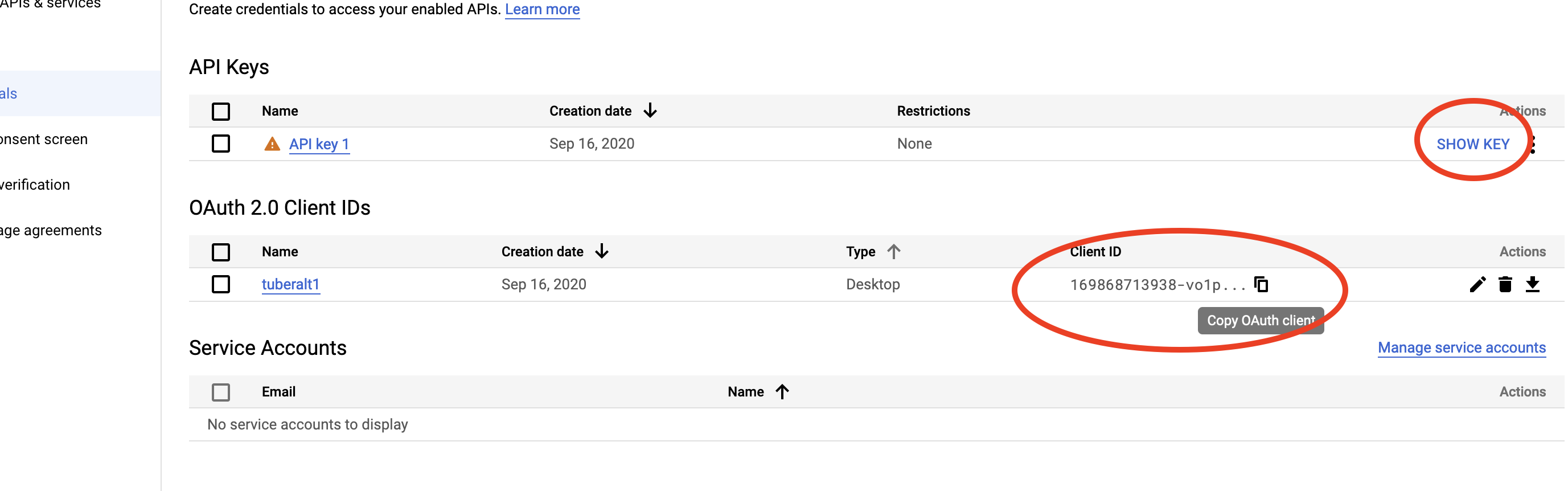
Once we have our credentials, we can log them in our R environment with the yt_oauth function in the tuber package. This function takes two arguments: an “app ID” and an “app secret”. Both of these will be provided to you once you have associated the YouTube API with your Google Cloud console project.
Getting YouTube data
In the paper by Haroon et al. (2022), the authors analyze the recommended videos for a particular used based on their watch history and on a seed video. In the below, we won’t replicate the first step but we will look at the recommended videos that appear based on a seed video.
In this case, our seed video is a video by Jordan Peterson predicting the death of mainstream media. This is fairly “alternative” content and is actively taking a stance against mainstream media. So does this mean YouTube will learn to recommend us away from mainstream content?
In the above, we first take the unique identifying code string for the video. You can find this in the url for the video as shown below.
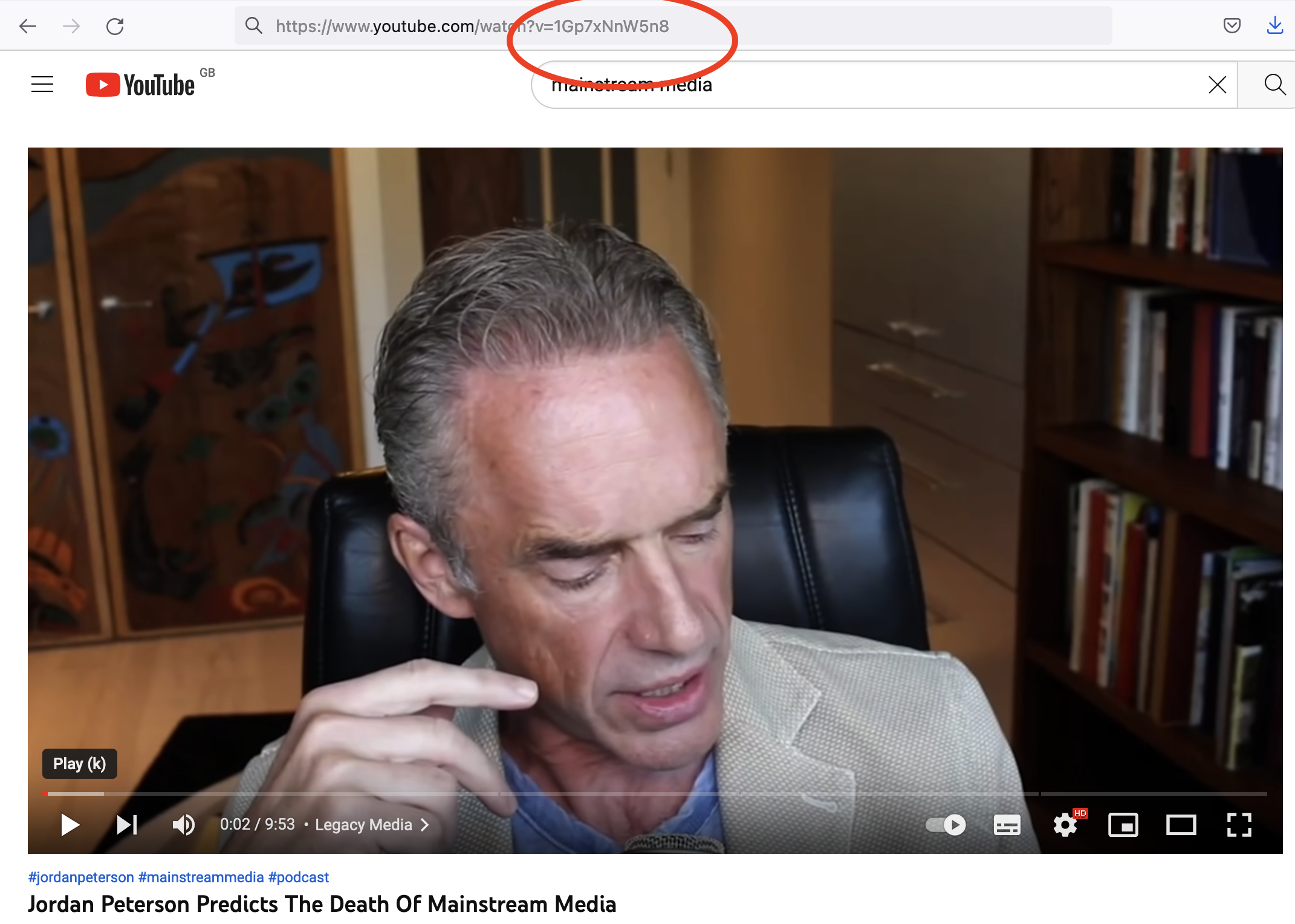
We can then collect the videos recommended on the basis of having this video as the seed video. We store these as the data.frame object rel_vids.
And we can have a look at the recommended videos on the basis of this seed video below.
It seems YouTube recommends us back a lot of videos relating to Jordan Peterson. Some of these are from more mainstream outlets; others are from more obscure sources.
Questions
Make your own request to the YouTube API for a different seed video.
Collect one video ID for each of the channels included in the resulting data
Write a for loop to collect recommended videos for each of these video IDs